Введение
Увеличение числа и изменение качества электронных документов на локальных компьютерах и в сети Интернет позволяют адаптировать известные алгоритмы и предлагать новые для более точного поиска. Поиск похожих объектов (similarity search), кроме поиска похожих текстовых документов, включает задачу поиска семантически близких слов, задачу поиска похожих вершин графа. Для поиска синонимов и семантически близких слов применяют методы, учитывающие структуру гиперссылок, частоту словосочетаний и др.
В методах поиска, использующих структуру гиперссылок, учитываются весовые коэффициенты, назначенные каждому документу (в наборе документов с гиперссылками). Это позволяет вычислить относительную важность документа внутри данного набора (концепция авторитетных страниц). Алгоритмы HITS [Kleinberg, 1999] и PageRank (реализован в Google) предназначены для поиска интернет страниц, соответствующих запросу. Эти же алгоритмы позволяют искать похожие страницы (similar pages).
Метод извлечения контекстно связанных слов на основе частотности словосочетаний [Pantel, 2000] предлагается для поиска контекстно похожих слов (КПС) и для машинного перевода. Данными для поиска КПС служат (1) семантически близкие слова из тезауруса, (2) словосочетания из БД с указанием типа связи между словами. Для слова w формируется cohort w, т.е. группа слов, связанных одинаковыми отношениями со словом w, из базы словосочетаний. КПС слова w – это пересечение множества похожих слов (из тезауруса) с cohort w. Работа [Pantel, 2000] интересна формулами, предлагаемыми для вычисления сходства между группами слов.
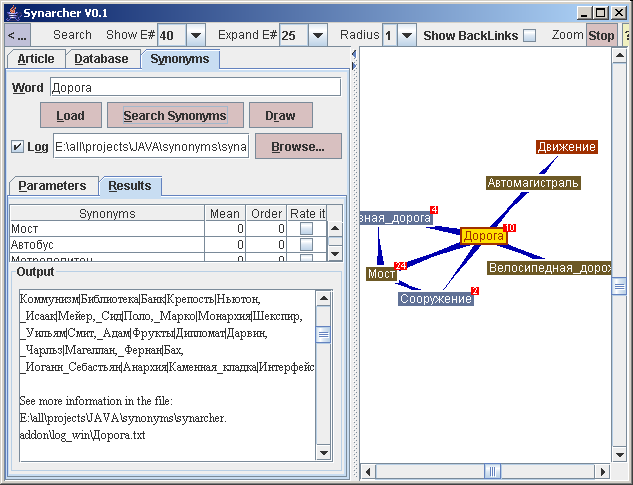
В данной работе представлен адаптированный HITS алгоритм и его реализация в виде программной системы для поиска семантических синонимов в корпусе текстов с гиперссылками и категориями (Википедиа).
Трудности поиска синонимов определяются рядом причин. Во-первых, автору не известно общепринятой количественной меры для определения степени синонимичности значений слов. Можно утверждать, что одна пара слов более синонимична чем другая, но не ясен способ однозначно указать во сколько раз. Во-вторых, понятие синонимии определено не для слов, а для значений слов, т.е. синонимия неразрывно связана с контекстом. В-третьих, язык – это вечноизменяемая субстанция. Слова могут устаревать или получать новые значения. Особенно активное словообразование и присвоение новых значений словам наблюдается в науке, в её молодых, активно развивающихся направлениях.
Разработанные алгоритмы используют структуру ссылок в текстах, поэтому могут применяться к текстам на любом языке. Ссылки, связывающие страницы друг с другом, указываются экспертом. Предлагаемые алгоритмы применимы к корпусам текстов с гиперссылками и категориями. Эти тексты должны отвечать следующим условиям:
Каждому текстовому документу (статье) соответствует одно или несколько ключевых слов, отражающих содержание статьи. Например, в случае энциклопедии – энциклопедической статье соответствует одно слово – название статьи.
Статьи связаны ссылками. Для каждой статьи определены: набор исходящих ссылок (на статьи, которые упоминаются в данной статье) и входящих ссылок (на статьи, которые сами ссылаются на данную статью).
Каждая статья соотнесена одной или нескольким категориям (тематика статьи). Категории образуют дерево таким образом, что для каждой категории есть родитель-категория (кроме корня) и один или несколько детей-категорий (кроме листьев).
Данная структура не является абстрактным измышлением. Она имеет конкретное воплощение в структурах типа вики (wiki), получивших широкое распространение в последнее время в Интернете, например, в виде электронной онлайн энциклопедии Википедиа (на русском, английском и других языках) (http://wikipedia.org). Анализ сетевого ресурса Википедиа представлен в [Holloway et al., 2005].
Алгоритмы, разработанные в системе, позволяют осуществлять поиск синонимов и близких по значению слов в английской и русской версии энциклопедии Википедиа. Причём нет принципиальных ограничений в применении программы к Википедиа на других языках, к вики ресурсам вообще и корпусам текстов, удовлетворяющих указанным выше требованиям.
Вики ресурсы
Кратко осветим тему вики ресурсов, поскольку Википедия является вики ресурсом. Перечислим значения слова. Вики (Wiki) – это тип сайтов, предоставляющих пользователям простой способ для добавления и изменения страниц сайта и, в особенности, предназначенных для совместной работы. Вики – это «простейшая онлайн база данных, которая, возможно, работает» [WhatIsWiki, 2005]. Также вики – это часть программного обеспечения (ПО) на стороне сервера, позволяющая пользователям создавать и редактировать содержание Интернет страниц с помощью любого Интернет броузера. Язык вики поддерживает гиперссылки (для создания ссылок между вики страницами) и является наглядным (по сравнению с HTML) и безопасным (нет JavaScript и Cascading Style Sheets) [Wiki, 2006].
Вики технологию изобрёл Ward Cunningham в 1995 г. Прелесть вики в том, что у каждой страницы есть ссылка “редактировать эту страницу”. Пользователи могут редактировать страницы, читатели легко превращаются в писателей.
Чтобы вносить правки, пользователи регистрируются. У каждой страницы есть ссылка “страница истории”. Ссылка ведёт на страницу, где указаны изменения, список авторов, упорядоченный по времени, и комментарии авторов к изменениям.
Концепция «свободного редактирования» имеет свои достоинства и недостатки. Открытость в редактировании текстов привлекает простых (технически не подкованных) пользователей, что позволяет развивать уже существующие вики ресурсы. К проблемам стоит отнести борьбу с вандализмом недружественных, а точнее, невежественных пользователей. Эта проблема решается благодаря возможности отката (в БД хранится история всех правок) и наличию истории страницы (указывается кто, что и когда правил). Решение об откате принимает администратор ресурса.
Тематическая связность авторитетных страниц
Авторитетные страницы – это страницы, соответствующие запросу, имеющие больший удельный вес среди страниц данной тематики, т.е. большее число страниц ссылаются на данную страницу. Hub страница содержит много ссылок на авторитетные страницы.
Задача – извлечь тематически связанные авторитетные страницы из коллекции страниц. Простейший подход: упорядочить страницы по степени захода (число ссылок на страницу). Проблема такой простой схемы ранжирования в том, что могут быть найдены страницы с большой степенью захода, но тематически несвязанные.
Возможны следующие решения задачи:
Решение HITS алгоритма. Авторитетные страницы (по данной тематике) содержат не только большое число входных ссылок, но и пересекаются между собой. Это обеспечивается hub страницами, содержащими ссылки сразу на несколько авторитетных страниц (одной тематики). Т.о., научившись вычислять значения authority и hub страницы, получаем набор авторитетных страниц (тематически связанных), соответствующих запросу (здесь – слову, для которого ищем синонимы).
Оригинальное решение (на основе решения HITS алгоритма). В Википедии каждой странице эксперты приписывают несколько категорий. Категории образуют дерево, т.е. у каждой категории есть категория-родитель и несколько детей. Такая тематическая определённость страниц позволяет найденный список синонимов (с помощью адаптированного HITS алгоритма) разбить на кластеры, каждый из которых соответствует одному из значений исходного слова.
HITS Алгоритм
В работе [Kleinberg, 1999] предлагается для поиска Интернет страниц (соответствующих запросу пользователя) использовать информацию, заложенную в гиперссылки. Демократическая природа Интернет позволяет использовать структуру ссылок как указатель значимости страниц (эта идея есть и в алгоритме PageRank). Страница p, ссылаясь на страницу q, полагает q авторитетной, стоящей ссылки. Для поиска существенно, что страница q соответствует тематике страницы p.
Каждой релевантной странице (найденной в алгоритме с помощью поискового сервера) сопоставляются веса a и h, которые показывают соответственно насколько страница является авторитетной и насколько она является хорошей hub страницей. В [Kleinberg, 1999] предлагаются следующие формулы для итеративного вычисления:
|
|
(1) |
|
|
(2) |
где hj и aj показывают, насколько страница j является хорошим указателем на релевантные страницы (т.е. hub) и насколько страница j является авторитетной страницей.
Таким образом, задачу поиска похожих Интернет страниц Kleinberg сводит к задаче поиска похожих вершин в графе на основе вычисления весов вершин.
Задача поиска похожих вершин в графе на основе весов hub и authority
Дан направленный граф G=(V, E),
где V – вершины (страницы), E – дуги
(ссылки), v – вершина графа. Для каждой страницы v
известны два списка: Г+(v) – это страницы,
на которые ссылается данная статья, и Г¯(v) – это
страницы, ссылающиеся на данную статью. Для каждой вершины
определены значения двух весовых коэффициентов authority и
hub:
![]() .
.
Необходимо найти набор вершин A, похожих на вершину v. Степень сходства (между v и A) будет тем выше, чем больше будет hub-вершин H, указывающих и на v и на вершины из A. При этом вершины А являются авторитетными, т.е. на них указывают многие вершины той же тематической направленности, что и исходная вершина v.
Формализуем понятия: похожие вершины и авторитетные вершины, т.е. формализуем постановку задачи.
Необходимо найти множество вершин A, которые являются (i) авторитетными вершинами для исходной вершины v (т.е. значение (3) велико относительно других подмножеств вершин той же мощности), (ii) похожими на исходную вершину v в смысле наличия множества вершин H, ссылающихся одновременно и на исходную вершину v и на вершины из А (4). H – это hub-вершины, т.е. значение (5) велико относительно других подмножеств вершин той же мощности. Задача – выбрать множество A авторитетных вершин и H hub вершин в значении (6), где k – это один из параметров алгоритма.
|
|
(3) |
|
|
(4) |
|
|
(5) |
|
|
(6) |
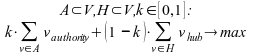
Назначение весов hub и authority вершинам-страницам может быть выполнено с помощью HITS алгоритма (формулы (1) и (2)).
Адаптированный HITS алгоритм с использованием методов кластеризации
HITS алгоритм был адаптирован с учётом таких возможностей вики ресурсов, как: наличие двух списков страниц для каждой статьи (кто ссылается на данную статью Г¯(v), на кого ссылается данная статья Г+(v)), наличие у статей категорий, определяющих их тематическую принадлежность.
Адаптированный алгоритм поиска включает шаги:
В корневой набор включаются те страницы, на которые ссылается исходная страница (вместо поиска с помощью поискового сервера в оригинальном HITS алгоритме).
В базовый набор включаются страницы, которые связаны ссылками с корневым набором.
Итеративно вычисляются веса с помощью формул (1) и (2) для поиска авторитетных и hub страниц среди страниц базового набора.
Алгоритм кластеризации на основе категорий статей (шаг отсутствует в оригинальном алгоритме).
Предлагается следующий алгоритм кластеризации статей (шаг 4) на основе категорий статей. Определим структуры данных, используемые в алгоритме и представим псевдокод алгоритма.
Переменные и структуры данных алгоритма кластеризации.
G=(V, E) – направленный граф , где V – вершины (статьи и категории, т.е. два типа вершин), E – дуги (три типа дуг: между статьями, между категориями, между статьями и категориями).
E sorted – массив рёбер, упорядоченный по весу (E sorted [0] – ребро с минимальным весом).
Clusters – список кластеров, которые нужно построить.
Для каждого ребра e определены следующие поля:
е c1 и е c2 – это указатели на два соединяемых кластера,
e weight – вес ребра, равный суммарному весу объединяемых кластеров с1 и с2.
Для кластера-вершины c определены такие поля:
|с edges| – число объединённых рёбер кластера (рёбер между вершинами-категориями кластера),
|с articles| – число статей, которые ссылаются на категории в кластере (знак мощности множества |.| используется в силу его наглядности, однако, поскольку |с articles| – это переменная, то ей можно присваивать значение (см. напр. строку 5b в алгоритме),
c weight – вес кластера.
Входные параметры.
MaxClusterWeight – максимально разрешённый вес кластера. При вычислении веса кластера учитываются: число статей в кластере, веса объединяемых кластеров.
Процесс кластеризации состоит из двух шагов: предобработка (инициализация массива кластеров, присвоение начальных значений полям вершин и рёбер) и сам алгоритм кластеризации.